Microsoft has started the work on Entity Framework V2.00 now. Apparently, this version will have a great deal more transparency during the process, making sure it ends up as something the users want.
Good stuff.
NHibernate, beware?
Update:
A petition against the current quality of Entity Framework has begun. Read it to get a brief overview of the issues, and add your signature if you agree.
Wednesday, June 25, 2008
Entity Framework V2.0
Tuesday, June 10, 2008
PropertyNamesGenerator (source)
I recently wrote the post Replace strings for property names with type-safe version
This is the source code for the project it describes. I'm posting it because of a request, so hopefully you'll have use for it.
PropertyNamesGenerator
- Generates type-safe versions of property/field names.
- Generates C# or VB files
- The only parser implemented is for parsing NHibernate mapping-files
The NHibernate parser handles regular classes as well as subclasses.
Another parser which will probably get there is for regular domain classes.
Warning: This is not production-grade software, but a simple project I made for myself to handle a current need! This should not be used as a guideline for good design, nor expected to work flawlessly. No such thing have been attempted.
You can download it here.
The zip includes the source, the current binary, and a sample bat-file to use it.
How to use it:
To run the generator, start it with something like:
- "C:\path\PropertyNamesGenerator.exe" /lang:cs /files:"../../source/Domain/*.hbm.xml" /out:"Output"
An explanation of the various params can be found by running it with a -? switch. It prints:
Run like: PropertyNamesGenerator.exe /files:"path/*.hbm.xml" /out:"path/PropertyNames/" /lang:cs
Parameters:
/Files [Mandatory] - Must have both a directory and a search string.
/Out [Mandatory] - Must specify an output directory.
/lang [Optional] - Output-language. C# or VB. (C# is default)
-V - Verbose output.
Note: All directories can be relative.
It currently only supports searching for files in the directories explicitly specified, i.e. not subdirectories. This is a concious choice.
To integrate it with your build, typically use a bat-file in the same manner as the Generate.bat example file included in the zip.
To integrate it with your build, you can add something like the line below to your Domain Pre-build event: (Project/Build Events)
call "$(SolutionDir)\..\Tools\PropertyNamesGenerator\Generate.bat"
Note that you will need a full path to the PropertyNamesGenerator.exe-file in the bat-file to use it like this.
It will generate files on the form [ClassName].[lang] in the output directory specified. Using a PropertyNames folder to put all of these in is recommended.
You will of course have to include these file in your solution to integrate them. Do this every time you have added and parsed a new hbm-file.
Thursday, June 5, 2008
Persistance-solutions and characteristics
The other day I invited my colleagues to a discussion about persistance solutions. The goal was to cover the various options for persistance in a software project, the pros and cons of each approach, and to increase everyone’s knowledge about it.
The approach planned was to identify the possible solutions, identify important characteristics to help compare each solution, and to go through each possibility.
The different types we identified were:
- Code generation
- Object relational mapper (custom made)
- Object relational mapper (commercial/open source)
- Row data gateway (Which would be active record with domain logic)
- Table data gateway (Dataset)
- Stored procedures/views
- Manual SQL
- Object database
And the characteristics in no particular order:
- Development time
- Flexibility
- Performance
- Stability
- Complexity
- Refactoring
- Expertise
- Effect/limitation/intrusion on system
- Rapid Application Development (RAD)-support
- Attachment to data type
- Amount of developers
- Company demands/guidelines
- What you are creating
I think it is best to start off by defining the characteristics; what they are and why they are important.
- Development time
- The time it takes to get your persistance solution ready to use and understood. This can either be the time it takes to configure and use an existing solution or the time it takes to develop your own.
- Flexibility
- The flexibility of the system in terms of handling the various storage challenges in a project. This also includes handling a system which inevitably grows and changes.
- Performance
- Obviously performance is important, right? This includes how the system performs in general, how it scales, how it can help handle special cases. A word of caution though: Even though performance is essential, don’t optimize prematurely. In any system of reasonable size, you will have special cases that will become bottlenecks. However, with a profiler and the possibility of fine-tuning those cases, you should be quite alright.
- Stability
- You need to know that the system won’t break down under normal usage or high peaks. Testing is essential for this.
- Complexity
- How complex is it to use and understand? How much help do you get with error messages? What do you when you need to debug? Is it too complex for the average developer on the project, making people take (eventually unmanageable) shortcuts?
- Refactoring
- What sort of help do you get when the need for refactoring appears (often)? How hard is it to do changes?
- Expertise
- You always need to take into account the expertise and skill level of the people on the project. This is more important that selecting “the best” solution.
- Effect/limitation/intrusion on system
- What does it take to integrate the persistance solution with your overall system? Will your domain model be POCO? Do you need to inherit from a base class? Implement an interface?
- Rapid Application Development (RAD)-support
- What kind of GUI-support does the solution have? If you need something quick and dirty, what do you do? The winner here should be pretty clear (If not, you’ll soon find out)
- Attachment to database data type
- How close is it tied to database data types? Can it for instance handle the types of several databases?
- Amount of developers
- How many developers the project has. This could influence the complexity of the solution, or the time available to get it up and running.
- Company demands/guidelines/policy
- Company policies/limitations are a part of normal life for a consultant, and often there is little you can do about it. The company might have policies against using anything open source, demand that all database access should go through stored procedures, etc.
- What can you do about this? Unless you have a small project or are able to influence the architecture group, chances are you’ll have to manage. I guess you can pray that the architecture group doesn’t consist of a bunch of non-coding architects that selects technologies out of marketing slides.
- Another point I need to raise here: If your company still live in the “don’t use open source”-world, chances are that most decision-makers are a bit out of sync with what is happening in the .NET world today. Agreed, just a few years ago things were pretty thin in terms of open source projects on .NET, but today things have most definitely turned to the better.
- What you are creating
- The most important point! Make sure whatever you choose will work for your project. Unneeded complexity is expensive! But remember that going from one solution to the other is often hard, so beware the danger of a project growing on a bad solution; you’ll have a tough time getting out of it
That should cover the basics of what is important to think about before choosing a persistance solution. Let’s get to the actual solutions!
Code generation
This involves generating the data access and potentially partly the domain model from your database schema. You specify rules for how you want things generated. There are a couple of potential problems with this approach.- If the software has a binary solution specifying the mapping, you’ll have no way to map two differing changes, which in effect means you can only have exclusive checkout. In a multi-person project this is highly unproductive, and don’t forget that you’ll be unable to use branches, as you can’t merge them later.
- The other is that once you want to add a field or property to a domain object, you’ll have to update the database structure and generate the files before you can use it. This does take some time. I’m not saying that most other approaches are must faster; the annoying thing is that you can’t simply add properties etc. during testing for instance.
I have to admit that I have limited knowledge of this type of persistance-solution, but I believe this approach could be successful. There is no reason why the general mapping solution between the database and domain objects should be any poorer than with a general OR-Mapper. It depends what extra functionality is available and how everything is implemented (works). By this I mean the SQL generated, how the session is handled, lazy loading, how it affects the domain model and system, if it supports queries or SQL/stored procedures for special cases, type safe support for anything and everything, maintainable/understandable script files, and a few more I probably forget at the moment.
Object relational mapper (custom made)
An OR-Mapper is a piece of software that handles the problem of transforming your domain objects data into its equivalent form in the database. Your domain model is made of objects and pointers; the database model is made of rows, columns, keys and relationships. These are very different ways of handling data.By creating your own OR-Mapper you will have to handle the problem of mapping from the domain model to the database for starter. This is just a small part of what you need to handle though, and to make it clear => There are slim chances that creating your own OR-Mapper will be beneficial for your project. Doing it will be time-consuming and error-prone, you will reinvent the wheel without need (See Object relational mapper (commercial/open source)), you will tie up your best resources for a substantial amount of time, you will have to implement a lot of added functionality to make it functional. Oh, and I doubt any project will wait before the mapper is finished before starting the rest of the development - which means some other form of temporary solution must be created.. (An object database might be the best choice in such a scenario.)
However, as a colleague commented, it is probably a dream for most developers to do it. Why? First, it’s complex, so you’ll learn heaps by doing it. Second, you don’t have to relate to the business side, so you really just define most of the tasks yourself. Perfect or what?
Object relational mapper (commercial/open source)
This is the same as above, except you use an already existing solution from a vendor or open source project. I recommend this approach.Why create your own OR-Mapper when great solutions already exist? If you choose a premade mapper you will (potentially) get:
- Shorter development time – You will need time to configure, use and understand the solution. This is time-consuming as well, but far easier than creating your own. Getting started should also be fairly easy, even though the tougher concepts need more time.
- There’s a chance that present/new developers have used the solution before
- A solution tested in many projects, which means less bugs and more working features.
- New versions at no development cost.
You need to live with a few risks though:
- Harder to customize and debug. You’ll have to use time on strange error messages which can make little sense.
- The company might stop development and support, or the developer base of an open source project could die out. If you create your own OR-Mapper, the main developer(s) could quit as well.
In general, getting something of the shelf is far cheaper than building it yourself, as long as your requirements are met. I believe that this solution most of the time far surpasses any positive effects of building it yourself.
Picking a mapper at random just by browsing some marketing slides are not the way to go. Make sure you thoroughly read specs and user feedback, or the best thing if possible: talk to people that has experience with what you are considering, if it is a popular solution they shouldn’t be too hard to find.
There are a range of solutions in this field, but personally I’ve had the pleasure of working with perhaps the most known of them: NHibernate. NHibernate is an open source OR-mapper, which is a port of the well known OR-Mapper Hibernate from the Java world. NHibernate is a great piece of software, it has been used on numerous projects, and quite a lot of information is available through blogs and forum.
I’m not going to list all the reasons to use NHibernate, a quick search on the web should give you that, but a few things:
- NHibernate lets you have (almost) POCO objects (You need to mark all persistable fields/properties as virtual. NHibernate subclasses your objects with the virtual proxy pattern, to give you lazy loading etc.)
- NHibernate has mapping files to map between your domain object and database. These enable easy modeling of inheritance, collections, etc.
- It is mostly type safe (with NHibernate Query Generator at least), except when you need to write advanced queries. (You could use something like my PropertyNamesGenerator though)
- You can use Hibernate Query Language to create special queries in the cases where performance isn’t good enough.
- Automatic lazy loading
A few bad things as well:
- There is some overhead involved, and performance has been noted as an issue on several occasions. I think this is more of a design issue with your average developer though. If you try to retrieve gazillions of data from lots of tables, you can’t expect it to be lightning fast. Proper table and index design, as well as good use of lazy loading should get you well under way. For the special cases where you do get a performance issue – use a profiler to see what the issue is, use query analyser to look at the SQL, use HQL or use manual SQL behind a well designed layer to access the data, use DTO’s to limit the data loaded and sent…. There are plenty of possibilities
- NHibernate has some strange error messages. Before you get to know it enough, you’re bound to use a few hours trying to figure out error messages which doesn’t make much sense. I base this on experience with the 1.2 version, not the new 2.0 release.
If you don’t want to go down the open source way, you’ve probably been (or will be) introduced to Microsofts new OR-Mapper Entity Framework. It’s Microsoft, so it’s bound to be good, right? (…)
Note: I have only read about Entity Framework, and thus my experience (both good and bad) are of questionable quality, so make sure you do your own research before making any conclusions.
The pros:
- Integrates nicely with LINQ (But Ayende has a project going to bring this to NHibernate as well
- Microsoft helps bring the concept of an OR-Mapper to public knowledge, which really is good
- With Microsoft’s size, there’s a good chance that the project will continue. This depends upon how many uses it of course; it might get shut down like Microsoft’s music service did.
- Developers versed exclusively in the Microsoft world have something besides datasets and manual ADO.NET to use.
The cons:
- They’ve built a completely new product - which means you should think they should be able to leverage the experience of already existing OR-mappers. You’ll need a good amount of resources to do this though. For some reason it doesn’t like Microsoft has quite lived up to this.
- Having read quite a few blogs about Entity Framework and spoken to Microsoft employees about it, I must say I’m initially skeptical. At least for enterprise development. According to one Microsoft employee, Entity Framework is only believed to have a third of its user group in the enterprise software world; the rest is your simple application developers. The needs are quite different.
- One of the aspects that alarms me quite a bit relating to enterprise development and Entity Framework (or really any modern type of development – read: with source control), is that until recently the mapping files were unmergable. (The XML created were put in a “random” order. A small change could lead to big changes in a document) I can’t for the life of it understand that Entity Framework could be designed as anything but a play version if that wasn’t an important design point from the beginning. Ayende had a post about a meeting he had with Microsoft about this point, and based on his reactions it seems likely that the team defended this decision. It seems Microsoft has improved this feature after the range of reactions on it, as mentioned here
- Explicit lazy loading. You have to explicitly say that you want to load a lazy-loadable collection. I think this sounds mostly annoying, as you need to fill your code with logic of testing if a collection has been loaded, and then explicitly loading it, compared to the NHibernate way of automatic lazy loading by simply using it. There is a good thing about it - the fact that you won’t get unexpected database calls from the GUI-layer because you forgot to load everything you needed. This could lead to a performance hit and other problems. I don’t believe that merits this solution.
Even though I’m skeptical about the current quality of Entity Framework, and would recommend using NHibernate instead, I’m positive to Microsoft’s general move into this realm. With their funds, future versions have the potential of becoming really useful, with hopefully seamless integration with the rest of the framework.
For now I’m mostly scared that I’ll be put on a project where its use will be mandatory. Unfortunately, we’re still in a world were non-Microsoft software is looked at with skepticism from many of the decision makers in companies.
Row data gateway (Which is Active Record if you have domain logic)
This is the same as having a gateway which gives you objects per row in the database. If you add domain logic to these objects you have what is called Active Record. I’m going to concentrate on the Active Record approach, as I can’t see a good reason why you’d want to have a simple row data gateway in .NET. Active record is a domain object which handles persisting itself.Active Record has the advantage of being simple and quick to implement. It is not hard to understand, and is a good way to make a quick prototype while retaining a domain model. It breaks down once your database gets complicated, and once you don’t have a one to one mapping between an Active Record object and a database table.
You can use Castle Active Record to do this. It is built on top of NHibernate. In terms of refactoring away from Active Record if the complexity increases, apparently there is a way to automatically go from Active Record to a full OR-Mapper NHibernate solution automatically. I haven’t tested this though.
(You’ll probably end up with a NHibernate solution through Castle then as well. This is not a bad thing! Castle integrates very well with NHIbernate through its NHibernateFacility, and easily allows for instance a Dependency Injection approach as well. I’ve written about it in a previous post)
Table data gateway (Dataset)
In the .NET world, table data gateway is the same as the dataset-approach.The major benefit of using datasets is the unmatched framework support for it, where creating a datagridview and datasource, using databinding, adding a navigator to handle paging, etc., is extremely simple and powerful. For quick demos, or Rapid Application Development (RAD), nothing can match it.
There are two main problems with this approach
- It really doesn’t scale. Once you start adding business logic, you’ll have problems with the lack of object orientation, with the lack of type safety, with duplication of logic, and lots more.
- Expectations, if you use it with prototypes. If you give the business side a quickly running demo with this approach, you’ll get into problems when you try to explain to them how long it will really take to build.
If you know you are creating a very isolated, not to be extended, solution, by all means use the dataset approach – nothing can match it in speed or simplicity. If there’s a chance you need to add more to it later, opt for another alternative. You’ll have a hard time refactoring it later on.
Stored procedures/views
Putting everything in stored procedures/views is another approach that has been used. I’m not going to bother saying much about it, as it’s not really a viable alternative. You’ll be better of using this approach than manually concatenating information into SQL queries though (Like avoiding SQL Injection attacks)It is a possible approach if you have special cases where you just can’t make the performance demands without using stored procedures.
Manual SQL
Don’t bother. But if you have to, at least limit its use to a database layer. And make sure you remove hazardous characters so you avoid SQL Injection.Object database
An alternative quite unlike the rest. Whereas the previous sections concentrated on ways of working with a relational database, you also have the option of using an object database. If you choose this approach you can just pass your objects to and from the database.Again, I haven’t tested this, but I have very experienced colleagues who have little but positive things to say about this approach.
The pros of this approach includes
- No need to map between a relational design and a domain model
- Don’t need to update a schema several places
- According to some benchmarks, they can be superior for certain kind of tasks. It has been said that they are very efficient at specific queries, while they are slower at more general queries.
- Most of the object databases also support some sort of query language when the need arises
- Some even fully support SQL, but I have no idea how this works in practice.
The cons
- Practical knowledge of these are still fairly limited
- Hard to access from other parts of the company network, for reporting purposes for instance
One approach some of my colleagues took was to go through the whole development period with an object database before converting to a NHibernate solution before going live. The conversion into a relational database was only done because of company demands. This was still a success, but if you do this you have the danger of not quite knowing how long it will take to set up the final solution or exactly how the data will perform.
I look forward to testing this in a real world project, you should too.
Conlusive thoughts
In summary I’d say that you should- Use the table data gateway/dataset approach if you have a short and sweet application
- Use Active Record if you need to get results fairly quickly, and have a close relationship between your table and domain structure
- Find out whether a commercial/open source OR-Mapper or code generation tool or an object database suits your needs best - if you need a somewhat complex application
- Build your own OR-mapper if you’re forced to, it’s not good for the project, but you’re lucky :)
Wednesday, June 4, 2008
Replace strings for property names with type-safe version
At times you have the misfortune of having to write property/field (I’ll just call it properties from now on) names as strings, for instance in advanced NHibernate queries. (In general, NHibernate Query Generator avoids this for you in most cases, but there are still some times it cannot be used. Say inheritance for instance). If you’re a bit slow on progressing in mocking tools, this might be a problem as well (It shouldn’t still be though…)
The big problem with non-type safe strings is refactoring, which should happen all the time on your projects. Property names will change, and when these are used as non-typesafe strings in your system it has a few unfortunate consequences:
- You could break something without knowing it. Worst case is you won’t find it until production
- The knowledge above could restrain you from doing refactorings.
- You will have to spend time doing text-searches in the system to find out if and where it is used.
So for a personal project I’m currently playing with, I figured I wanted to do something about it. So I created a small generator project which generates static classes where you have access to the domain objects property names in a type safe manner. What this does for me is:
- If I do changes to a property of a domain object, and that has been used as a (previously) non-type safe identifier, my compiler will complain.
- I can do refactorings all the time without worry.
For now it looks for instance like this in use:

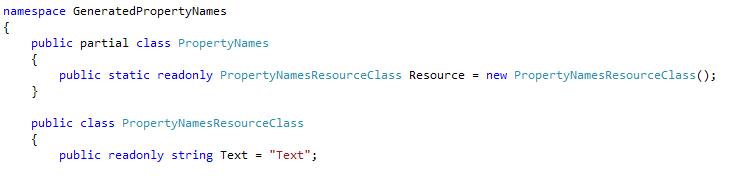
This will return “Text”, which is the name of a property in the Resource class or a base class.
I’ll be the first to admit that this is not ideal. Property names as strings are not something you want to deal with, but at times you have no choice, and this feels like the better of the two options.
For those interested in how I chose to solve it:
The generator takes in an input path, a search string and an output path. This is put in a bat-file which is called from the domain projects build. Currently I’ve only implemented a parser for NHibernate mapping files (HBM), which for each class creates a file with each property listed for that class. (I can see situations where you would want to use properties not just used in persistance, but that’s all I need for now). Inheritance is handled by duplicating the properties of the base class in the subclasses.
In short, the file created for the example above looks like:
Subscribe to:
Comments (Atom)