A few days ago we once again had a "fagdag" - a full day dedicated to learning (and a splendid evening building team spirit afterwards of course).
I held a presentation about the different ways to handle the object-database issue, focusing mainly on the positives and negatives of the various approaches, thus, I believe, providing more value than giving any sort of tutorial on tools or approaches which can easily be googled.
The goal of the talk was to make sure that all my colleagues were up to speed on what is available in this area today, and what should be used when.
Here's a brief overview of what I talked about.
The issue is the difference between objects and relational databases. Databases focuses mainly on storage and (more or less) normalized relationships through keys, while objects focus mostly on the interaction between objects in a business domain. They typically have the concepts of inheritance and polymorphism close at hand, while databases only handles these if they must, and definitely not naturally. the approaches from the object or database side certainly don't go hand in hand, neither technically nor conceptually.
So which options do we have for handling the object-relational impedance mismatch, and what's the pros and cons of each approach?
I covered the following approaches:
- Manual SQL
- Stored procedures/views
- Dataset
- Active Record
- OR-mapper (self-made)
- OR-mapper (open source/commercial)
- Code generation
As well as a few concrete implementations of active record and OR-mapper:
- NHibernate
- Linq To SQL
- Entity Framework
- Castle Active Record
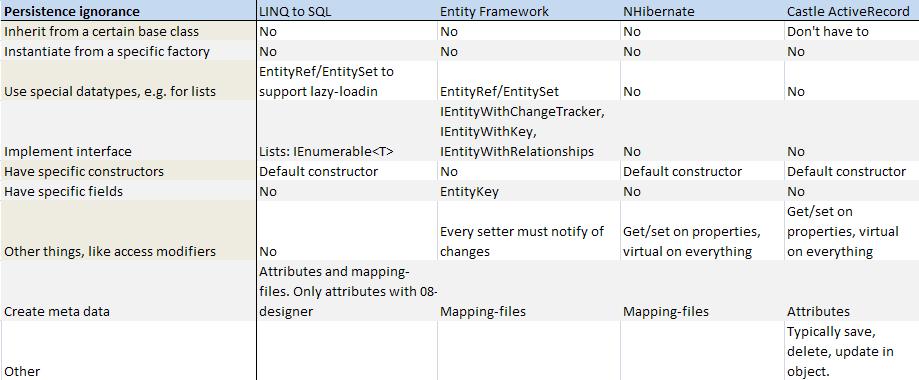
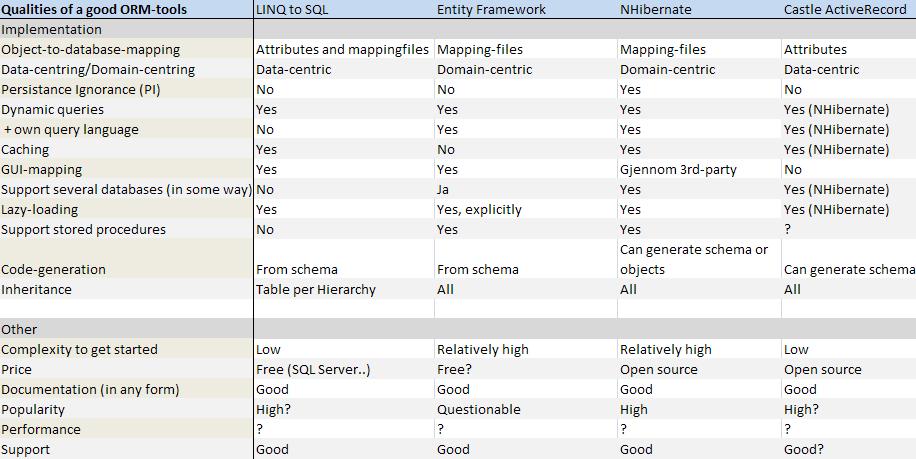
One concept important to have in mind when comparing many of these options is Persistence Ignorance. This means the degree of which your domain model is freed from having any reference or concerns about how the entity should be persisted. A large degree of Persistence Ignorance means you can model your domain model without any restrictions or interruptive information. Note that this does not correlate with how easy the solution is to use in general.
Manual SQL
Often used with datasets or "manual" OR-mapping.
Pros
- Easy to use
Cons
- Can be hard to handle / loose overview
- You need to write lot's of code
- No indication to the DBA what accesses the database
- SQL-injection
- Query plan caching - if you run a query against SQL Server without using parameters properly, the entire query will be cached, whereas if you use proper parameters the query excluding the parameters will be cached - meaning you can reuse the cached query plan with any number of queries with different parameters.
Stored procedures / Views
Often used with datasets or "manual" OR-mapping.
Pros
- Easier for the DBA to know what accesses the database
- Well known
- Great for batches and reports
- Could be used well as a layer of abstraction
- Security if you can't handle it on the application layer or when several applications must access the database and you need a central handling of it. You should have a good reason for doing this.
- Tuning of queries
Cons
- Can be time-consuming to specify everything as stored procedures
- If business logic starts leaking into your stored procedures you're in problems
- Switch database type. Not usually an issue, but if you are planning on changing databases anytime soon, don't model everything in stored procedures.
- I believe it's more hostile to change than many other options.
- Error messages and debugging is less clear
- (Testing. This is being used by many as a reason against stored procedures. I don't agree with this, becuase stored procedures are really quite easy to unit test, as long as you keep them clear and concise and don't go superdynamic on them)
Dataset
Pros
- Rapid Application Development(RAD) support
- Very quick to get up
- Support throughout the .NET framework
- Microsoft product. Easy to get a customer into
- Quick to get going, can be sure that everyone involved in a project will know of it.
Cons
- Scales very poorly with complexity
- Often need to live with utility-classes for functionality
- The database schema often leaks down into the code, frequently even into the GUI-binding. Try changing anything there..
- Not exactly an object oriented approach
- Everything must be casted (stored as object)
- String-based access to table and column-names (Unless you're using typed datasets)
- Since they're so easy to use and can be filled anywhere, some solutions even fills them in the codebehind. Oh beware
Active Record
Row object (entity) with domain logic and knowledge of how to persist itself. 1-1 mapping towards a database table.
Pros
- Easy to get started
- Not duplicated mapping of property names as in OR-mapping with mapping files
- Mapping against database in object. Nice to have everything in one spot
- Centralised connection to the database in one layer
- Always works with entities. Automagic queries to the database
Cons
- Works well with a uncomplicated schema (1:1). As soon as your domain model won't map well with the database schema, Active Record won't do for you.
- Data centric. Active Record says your objects need to be the same as your database tables. In simple approaches this works well. But as I mentioned briefly in the beginning, what you care about when you model the database is often very different from what you want and need when you model the domain model. Thus an active record approach can produce a domain model which is unclear and bothersome to work with.
- Hard for the DBA to tune queries
- Not big on Persistence Ignorance (PI)
- Testing can be an issue because of the point above
OR-mapper
Automatic mapping between database and objects through mapping files or attributes
General
-------
Pros
- Domain centric approach. Can model the domain separately from the database (to some extent)
- Dynamic SQL-generation
- Support multiple databases (At the same time or simplify switching at a point in time)
- Good solutions have support for stored procedures and/or manual SQL in the cases where you need to do things on your own
- Fast development-time once up and running
Cons
- Complexity (will get back to it)
- Performance (will get back to it)
With mapping-files
------------------
Pros
- Separated object and mapping
Cons
- Must duplicate class name, property names etc.
- XML and pure text (Help with GUI-support, advanced plugins)
OR-mapper developed in-house
----------------------------
Pros
- Own functionality
- Debugging can be easier / possible
- Know that everything that affects a project is internal
- Cool for the one doing it
Cons
- Time-consuming
- Need to redevelop something already developed a myriad of times
- Noone will continue development and testing of your solution outside of the project/organisation
- Anyone new to the project won't know the solution
OR-mapper - commercial/open source
----------------------------------
Pros
- Relatively short startup time (compared to creating it yourself, not compared with most other approaches)
- Advanced functionality available
- Well tested in projects and scenarios
- Free bugfixing and new releases
- New project members might know the solution
- User group with knowledge of its use
Cons
- Does take time
- Can't debug on errors (Might be possible)
- (Generally) limited by the products limits
- Learning curve
- If it's not Microsoft, it might be an issue in your organisation (hope not)
- What if the product go out of production/stops further development?
Code generation
Generate data access and domain objects from database
I don't know this area too well myself, so I'll be short here
Pros
- Advanced generation scrips
- With so many solutions available, there must be something good?
Cons
- Data-centric
- Many of the same cons as with OR-mapper, in terms of complexity etc.
And then it's the concrete implementations:
NHibernate
- Most known and mature
- Port from Hibernate, well known and have existed for a long time
- Large crowd of followers
- Domain centric
- Functionality
-- Mapping files
-- Inheritance (all three approaches)
-- Stored procedure support
-- All types of relationships (1-1, 1-*, *-*)
-- Caching
-- Support multiple databases
-- LINQ to NHibernate
-Persistence Ignorance (PI). Only need to set everything virtual and have a default (any visibility) constructor
I believe it's the de-facto OR-mapper in .NET at the moment.
Entity Framework
MSDN: "Designed to provide strongly typed LINQ access for applications requring a more flexible object-relational mapping, across Microsoft SQL Server and third-party databases"
- Enterprise solution
- Several layers of mapping (Conceptual, Storage, Mapping)
- Is supposed to be more than an OR-mapper (Don't deliver on this in V1)
- Poor in terms of Persistence Ignorance
- Not very mature
But I'm positive to Microsofts entry into this arena. The fact that they don't believe datasets can solve every problem in the world anymore is a big step forward. Also, they have taken all the criticism to heart, and have started fixing many of the shortcomings for v2. They also have a blog describing the work and asking for feedback, as well as an expert group following the progress. That is good stuff. Still hope I don't have to work with it yet becuase of some fancy marketing slide though. But hopefully it does become a good contender for the OR-mapping crown, what could be better than better tools?
LINQ to SQL
MSDN: "Designed to provide strongly typed LINQ access for raplidly developed applications across the Microsoft SQL Server family of databases."
- Good for RAD-development
- Support only direct 1:1 mapping towards the database
- Only table-per-hierarchy inheritance
- Only attribute-mapping when you use the 08 designer
- Only SQL Server (Though this apparently wasn't becuase of any technical challenge.)
Castle Active Record
Pros
- Simple to get started
- Created on top of NHibernate, taking advantage of all it has to offer, as well as making it much simpler to get started
- Don't need to specify column name in the attribute if it is the same as the property name
Cons
- Standard problems with PI for Active Record
- Common to inherit from base class (although you don't have to)
- Data-centric
- 1:1
I created a couple of diagrams to help compare the four approaches in terms of Peristence Ignorance and OR-mapping in general: