The purpose of this post is to pass on knowledge about an important aspect of software development, with the hopes that someone else can have use for it. It is a presentation I held at work changed into written form.
The topic is managing dependencies between objects; how it affects the systems we build, and a few thoughts on different ways to handle it. We are going to look at three patterns: Factory, Service Locator and Dependency Injection, which in various ways help us control the dependencies. The purpose here is not to explore all the details of the various patterns, but rather to capture how the patterns handle these situations in general.
As a way of comparing the patterns, I’ve put together a few well known principles that has important things to say on the quality of software.
Simplicity
- Complexity is so important to handle. Complex code is hard to read, change and manage. The challenge is to write code that people understand, not just code that compiles.
- Software that separates its different parts well is easier to understand and manage. The more a unit of code,which from now on should be understood as either a module, class or method, handles only a separate piece of the puzzle, the better. The Single Responsibility Principle fits well here: One unit of code should do only one thing, and do it very well.
- How much your unit of code depends on other parts of the system. Less coupling means code that is easier to understand, maintain and reuse in different contexts.
- Highly related to all of the points above. We want code that is easy to change. The reason for this is of course that there are few environments were things change more often, be it because of business or technological needs, or really just realizing the nature of most software projects.
- Design choices that are not important to know of outside of your unit of code, should not be visible there either. It only increases complexity, makes things harder to change, and removes focus from what is really important.
- Highly testable code has a number of benefits for the quality of your system, and is an important principle to live up to for the vast majority of projects.
I have created an example we will use throughout the post. It consists of two elements, a client and a service. The simplicity makes it impossible not to understand, as well as hopefully easier to relate to a number of situations, though making it harder to show real world problems and their solutions directly.
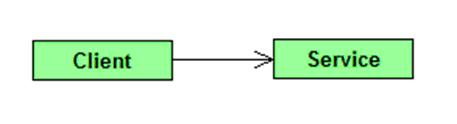
The service could be anything from an in-process calculator to an expensive web service or database service. The context has a lot to say for the conclusions, and it is vital that you relate the examples that will follow to the many similar situations you see on a daily basis. Depending on whether we would expect change here, we might or might not include an interface.
This is an example of the implementation of Client (in C#):

Potential problems with this code
- It is hard to change, because it is connected to a concrete implementation of the service in the constructor.
- You need to read the Client code to find that it has a dependency to Service.
- Testability would be hurt if this was a resource-expensive or unreliable service.
- It might do exactly what it needs to do - If it seems natural that Client should be responsible for creating Service, if there is no benefit of changing the implementation of Service in different situations, if testing isn’t hurt by not accessing it, then by all means keep it as simple as you can. YAGNI (You ain’t gonna need it) and KISS (Keep it simple, stupid) are important principles to follow.
- As a side note concerning testing: It is possible to test this with TypeMock.
What if we increase the complexity of this example? Let's add an IStorageObject, which is a common interface for two ways of storing data, DatabaseObject and CacheObject. As the diagram below shows, Service now has a dependency towards DatabaseObject (And to IStorageObject, though not shown explicitly).

And the implementation:

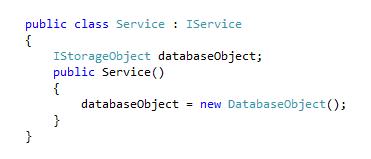
As simple as this example is, we already have a potential for tight coupling. Even though we are coding to interfaces, this is not that easy to change. Reusing Client or Service in a different context is very hard. Replacing the implementation with a mock or stub during testing is in most cases impossible. And even though this example hides it, both Service and Client is now responsible for both creating and using the dependency, responsibilities we often want to separate (e.g. because of complex initialization). In real life, the complexities and couplings are often increased tenfold, and only then can you see the true value of these principles.
Pattern #1 - Factory
The factory pattern is one of the GoF patterns, a creational pattern, responsible only for creating objects. I have created a dead simple implementation of the factory pattern, where you have a ServiceFactory class with a static method to give you the concrete instance you want.
The dependencies can be modeled like this:
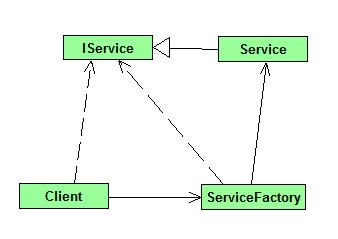
Advantages
- Client only has a direct dependency on IService now, not the concrete initialization.
- The code is more testable, if we have a factory where we can switch the concrete instance with a mock object.
- The usage of Service will be clearer and easier to start using as all creational logic has been separated.
- Having a single place to get instances of a service means you have more general possibilities, like the transparent handling of instances (always new or singleton). I will look at others throughout this and the next post.
- We have separated the responsibility of creating and using the service. If creating a service means several manual steps to configure it, then this is even more valuable.
- The Factory could return a different implementation based on input, a common reason to use a factory.
- In our situation, we still have a compile time dependency on the specific IService implementation. The dependency has only moved a step out.
- Reuse of Client in different contexts is hard, because of the still tight coupling to Service.
- If we look back at the example with the deeper dependencies. Should we make another factory to handle this creation? Has this really loosened the coupling that much, and do we want to use all our time writing boilerplate factory-code?
- We still have to read the implementation of Client to find that it has a dependency towards Service.
That being said, let’s look at how it lives up to the different principles listed in the beginning
Simplicity
- The factory pattern is easy to use, and is one of the most known patterns. Thus, using it will help give clarity to what you try to achieve, even to developers less versed in the "patterns world". Though it is not correct in every situation, and too many factories is not necessarily a good thing either.
- The creation and use of a dependency is separated.
- The example still has a compile time dependency on the concrete implementation of IService. In many cases the factory pattern can help with the coupling, for instance by sending in some form of input.
- Reusing Client in a different context is hard because of the still tight coupling.
- If the implementation of the factory allows you to switch implementations, then yes, it is more testable. You need to initialize the factory with every test however, and even switch back again to the previous implementation to make sure that you don’t break other tests.
Pattern #2 – Service Locator
An (potentially global) object that gives access to services the application needs.The example changes to:

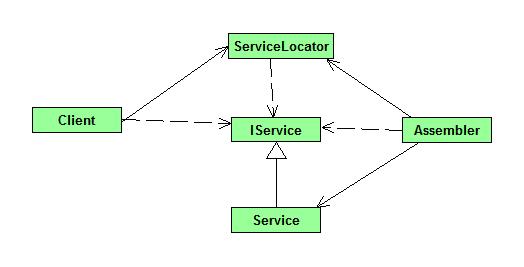
Instead of the factory class we now have the service locator that creates and/or returns the service. The biggest change here is that you now have an assembler class which typically configures the Service Locator with the correct instances.
Two points concerning the implementation
- In the example above I have used a string to get the correct type of service. This might as well have been solved with sending in a type or using generics if you want type safety and support for refactoring, at the cost of some flexibility though.
- The example uses a Service Locator interface to separate the LocateService method from the methods Assembler uses to register services. The implementation is still a singleton, and could be changed to not use GetInstance first.
Advantages
- Encapsulates the logic to find services.
- A separate interface to deal with.
- A central point of control. Easier to do similar things with the services you get, like handling instances and caching.
- Can add a mock implementation during testing.
- Hard to handle deeper dependencies well.
- Advanced initialization of objects, which the factory does so well, is hard.
- Possibly code to reset the service locator to make sure that one test does not break others.
And onto the principles:
Simplicity
- Easy to use. A single method to call.
- The creation and use of a dependency is separated.
- If you have an implementation that uses an XML file to configure up the specific instances, then there is no compile time dependency.
- As there is less coupling, it is easier to change as well. Reusing Client in a different context is still often troublesome though.
- This pattern does make it even easier to test than Factory, but you still have to write extra code to create and change the service locator.
Pattern #3 – Inversion of Control / Dependency Injection
A fancy word for a really simple principle: it simply means injecting dependencies.
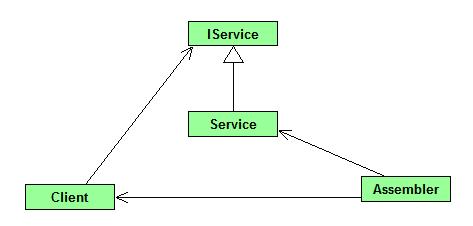
As you can see in the images above, Client now receives the specific implementation of IService from the outside.
Before going further, I think it is necessary to write a couple of lines about the confusion concerning the two concepts Inversion of Control and Dependency Injection. Inversion of Control is a common concept in computing. It relates to a situation where you instead of taking the active approach and asking for something, the framework is the active part that calls you. (i.e. events, the startup method of an application, etc) Dependency Injection is a specific form of Inversion of Control, where instead of asking for a specific dependency (As was done with Factory and Service Locator), the dependency is handed to you.
There are three types of Dependency Injection: Constructor, Setter and Interface injection.
Constructor injection
- what is shown above, injecting the dependencies in the constructor.
Advantages
- Any user of Client will see that it has a dependency on IService.
- Unlike the other injection approaches, Client is completely initialized once created, as you can’t create it without giving it an instance of IService.
- You can set IService as ReadOnly, since it is set in the constructor.
- If you have optional dependencies, especially if they are resource-intensive to create, then it is not a good idea to initialize them in the constructor.
- If you have many optional dependencies, and want to give a separate constructor for each valid case, then you soon end up with a lot of constructors.
Setter injection
- Injecting the dependency through a property.

Advantages
- Good way to handle optional dependencies, especially if they are resource-intensive.
- Support for Dependency Injection in legacy code without having to change the constructor, for instance to improve testing, or to add new functionality.
- Harder to know what you need to do to use the object, which can lead to surprises.
- Somewhat harder to track down exceptions.
Interface injection
– a special form of setter injection: Specifying injector methods in an interface.
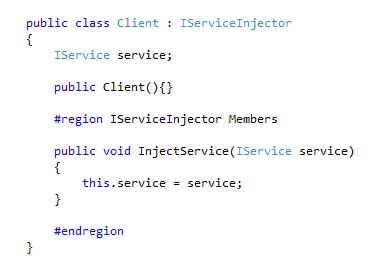
As this is almost identifcal to Setter injection, there isn’t much else to say about it. The only difference is that it can help separate out what are really dependencies that must be filled. However, this seems to be the least used form of dependency injection.
Advantages of using Dependency Injection in general
- Easier to test: You can simply inject a mock.
- Potential for less coupling, as it doesn’t ask for a specific implementation.
- Easy to reuse Client in different contexts, because of the point above.
- Not necessarily compile time binding. And even if so, different implementations of Client can easily be bound to different implementation of IService.
- You’re not supposed to inject everything. One problem is that you can break encapsulation, another that you should take care not to create interfaces for all objects in your system. Coding to interfaces is a good thing, but making interfaces where you don’t expect change or testing isn’t a good enough reason, will make it hard to see where you truly expect change in the system.
- It can be cumbersome to do Dependency Injection manually. I look at a solution for that in my next post.
So how does Dependency Injection live up to the initial principles?
Simplicity
- Simple to write and understand. But writing manually can be time-consuming.
- The creation and use of a dependency is separated. Also, Client only uses the dependency now. Compared to the other patterns, Client doesn’t even need to ask for an implementation.
- The code has a potential for even less coupling, as it only uses it's dependencies.
- Easy to change in terms of using Client in different contexts, but manual dependency injection code isn’t any easier to change.
- Don’t break encapsulation where it’s not natural.
- By far the easiest way of testing objects where you need to add a mock implementation.
References and further reading
Inversion of Control Containers and the Dependency Injection pattern [Martin Fowler]A few of the posts on a longer discussion of Dependency Injection: (You can find more from each)
Dependency Injection
Dependency Injection: More than a testing seam
Defending Dependency Injection
Dependency Injection - Keep your privates to yourself
Dependency Injection - MSDN Magazine
Guice video. Some good general points as well, if you're bored with reading.
Applying Domain-Driven Design and Patterns (Book) - On Dependency Injection and Service Locator
GoF (Book) - On Factory
Head First Design Patterns (Book) - On Factory
Conclusive thoughts
At the outset of creating this presentation, I was planning to only write about the Dependency Injection pattern. However, I felt that putting it in a bigger context, and trying to present the different patterns in a more uncommon way would be more helpful. This is by far perfect, but if it can help anyone better see the usage of these patterns and part of their place in the world, then it was worth rewriting this for the web. Not the least, if anyone can further educate me as well, what could be better?This was part 1 of the presentation. Part 2 handles IoC Containers, and how you can do Dependecy Injection without having to do it manually.
No comments:
Post a Comment